
DeathStarBench is a benchmarking suite developed by the SAIL group at Cornell University. It is completely open-source and can be found at https://github.com/delimitrou/DeathStarBench.
This document is WIP.
Design Philosophy
Datacenters are shifting from complex monolithic services that handle all functionality in a single binary to graphs of tens of hundreds of single-purpose, loosely-coupled microservices. This has broad implications for cloud management, programming frameworks, operating systems, and datacenter hardware design.
This suite aims to include several end-to-end applications with tens of microservices, each to represent a cloud workload with lots of microservices.
Repo Watch
Applications are distributed with Docker Compose, with Helm charts provided.
It makes it easy to evaluate this benchmark on a platform with full Linux kernel and virtualization support but hard to evaluate micro-architectural changes with no taped-out chips or OS support.
Workloads and Properties
Social Network
A broadcast-style social network with uni-directional follow relationships.
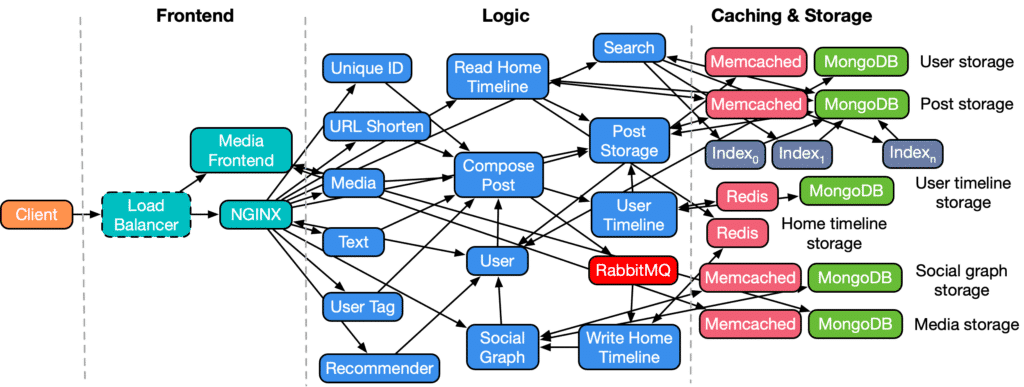
All applications downstream php-fpm uses Apache Thrift RPC framework.
Key workloads in this application:
- The majority of microservices are written in C++.
- New posts will be broadcasted to all followers with RabbitMQ, which probably means lots of traffic and database keying.
- Includes some machine learning:
recommendersandads.searchuses Xapian. - It uses MongoDB, a scalable key-value interface.
Media Service
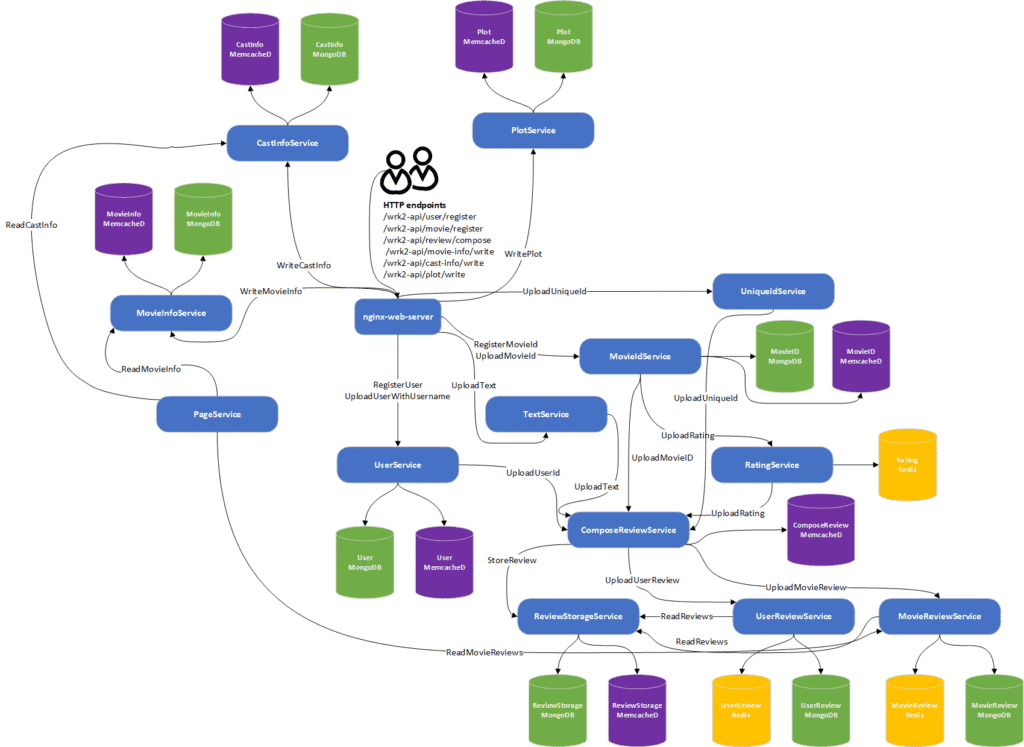
This application has many similarities with the social media application, with some differences worth mentioning:
- It contained a MySQL database, which is a relational database and functionally less scalable than MongoDB (if you shard them correctly, that is).
- It contained an NFS remote file server for storing large media files and chunking.
Hotel Reservation
Less is known about this workload since it is only released in the GitHub repository, not in the original paper. It is written in Golang, and it seems to have a static frontend. Communication between microservices is done with gRPC.
Though this application also contained search and recommend, they seem to be purely based on geographical distance, with no indexing or ranking whatsoever.
Unreleased Applications
The paper claims to have an E-Commerce Service, Banking System, and Drone Swarm Coordination system, but they were not present in the GitHub repository.
Traffic Generation & Tracing
All released applications contained Lua scripts for generating traffic into the application. They seem, however, to be unit tests instead of an emulation of what a user could do. It seems possible to generate a lot of requests to pressure test the service, but there is no way to configure the balance of each kind of request.
Applications using Apache Thrift have distributed tracing, using Thrift's timing interface to trace when requests arrive and depart from each microservice. gRPC did not have that feature built in, and Hotel Reservation using gRPC doesn't seem to integrate that functionality.
Their Evaluation Results and Implications
The authors of DeathStarBench evaluated these microservices on a cluster of well-equipped servers, with more than enough cores to give each container their dedicated core. Here are their observations:
- A large portion of cycles, often a majority, is spent on the processor front-end (instruction fetch), but to a lesser extent than monolithic cloud services, due to their smaller code footprint.
- Less portion of branch misprediction stalls.
- Better I-cache locality and less I-cache misses.
- ML Applications have extremely low IPC.
- Interactive services still achieve better latency in servers that optimize for single-thread performance.
- Microservices are much more sensitive to poor single-thread performance than traditional cloud applications.
- Using an 48-core In-Order ARM (Cavium ThunderX) achieves similar E2E latency under low loads but saturate earlier in QPS - But this might be an unfair comparison: 20 Xeon servers vs 2 ThunderX boards.
- Large number of cycles in the kernel: interrupts, TCP processing, waiting for IO, etc.
- NIC queueing becomes dominant at high load
- Offloading TCP to an FPGA provided 10-68x speedup in communication. 2.2x tail latency.
- Network Acceleration provides a major boost in performance
- Pressure on back-end services will propagate high latency to frontend. Hotspots propagate between tiers.
- The cluster management platform does not always identify the app to scale out.
- Using higher-level, less efficient programming languages for microservices cause bottlenecks, which saturates mid-tier services before they propagate to backend databases.
- A slow server in a cluster is detrimental to overall performance.
Comments NOTHING